A permutation test, also known as a randomization test, is a non-parametric statistical test used to determine if there is a significant difference between two or more groups. Unlike the bootstrap method, which involves resampling with replacement, permutation tests involve resampling without replacement.
Hypotheses in Permutation Tests
Permutation tests are often used to test the null hypothesis \(H_0\) that two distributions, \(f\) and \(g\), are identical, against the alternative hypothesis \(H_1\) that they are different.
Null Hypothesis (\(H_0\)): \(f = g\)
Alternative Hypothesis (\(H_1\)): \(f \neq g\)
They are called non-parametric because they do not assume any specific distribution of the data.
Methodology
Data Setup: Assume we have two groups of data:
\(x_1, x_2, \ldots, x_n\) from distribution \(f\)
\(y_1, y_2, \ldots, y_m\) from distribution \(g\)
Define the combined ordered set \(z = (x_1, x_2, \ldots, x_n, y_1, y_2, \ldots, y_m)\) with \(N = n + m\).
Permutations: Let \(\pi_i\) denote a permutation that samples \(n\) elements from \(N\) without replacement. There are \(\binom{N}{n}\) possible permutations.
Each permutation \(Z_{\pi_i}\) rearranges \(Z\) such that the first \(n\) elements are considered as group \(x\) and the remaining \(m\) elements as group \(y\).
Test Statistic: Define a test statistic \(\hat{\theta}(Z)\) based on the observed data. For example, if comparing means, it could be:
\[
\hat{\theta} = \bar{Y}_B - \bar{X}_A
\]
where \(\bar{Y}_B\) and \(\bar{X}_A\) are the sample means of the two groups.
For each permutation \(Z_{\pi_i}\), compute the statistic \(\hat{\theta}(Z_{\pi_i})\). This creates a permutation distribution of the test statistic.
Example: Testing Means
Consider two observations from groups A and B:
Group A: \(3, 4\)
Group B: \(5, 6\)
We want to test if the two groups have the same mean at the 0.05 significance level.
Since the p-value \(\frac{1}{3}\) is greater than 0.05, we do not reject \(H_0\).
Exact and Approximate Tests
Exact Test: Uses all \(\binom{N}{n}\) permutations. The p-value is the fraction of permutations where the test statistic is as extreme or more extreme than the observed value.
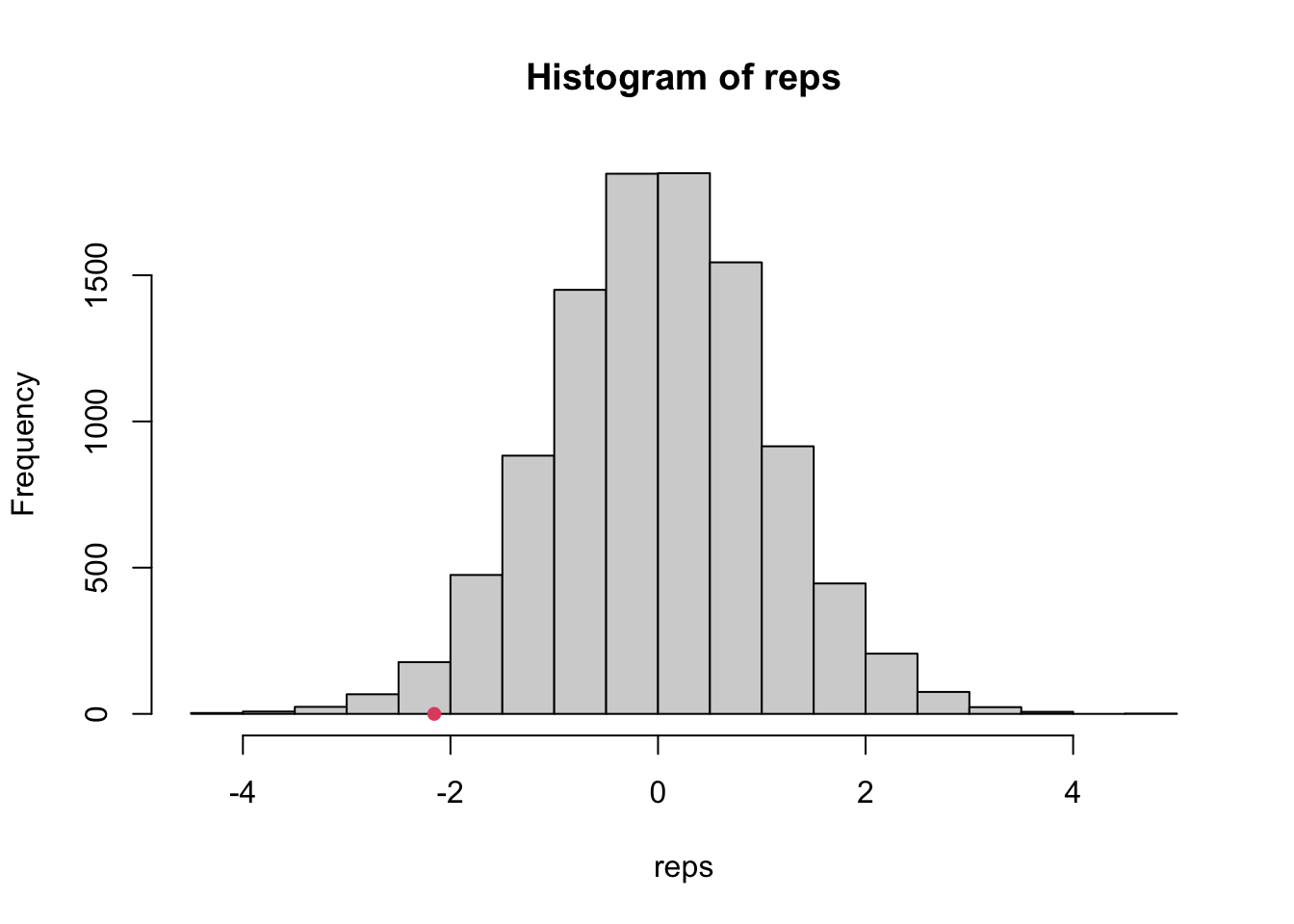
# Counting the number of times the replicates are more extreme than the observedpval <-mean(abs(reps) >abs(observed))pval
[1] 0.0417
observed_p <-t.test(x, y)$p.valueobserved_p
[1] 0.04441462
Explanation: The code permutes the combined dataset, creates new datasets of the same size as the original groups, and calculates the t-statistic for each permutation. The p-value is the fraction of permutations where the test statistic is more extreme than the observed statistic. A low p-value indicates that the observed value is unlikely under the null hypothesis, leading us to reject \(H_0\).